





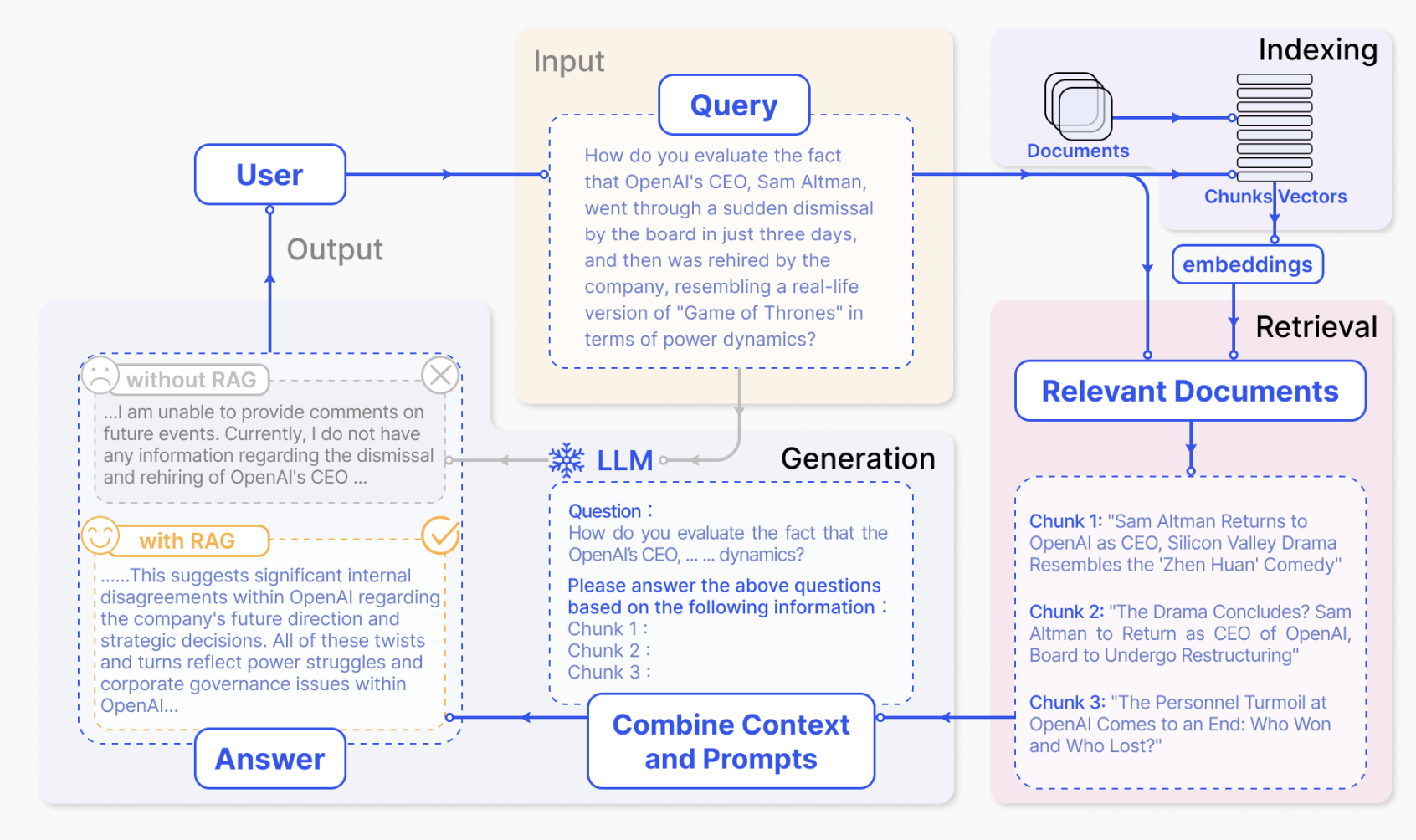
Retrieval-augmented generation (RAG) is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal representation of information. Implementing RAG in an LLM-based question answering system has two main benefits: It ensures that the model has access to the most current, reliable facts, and that users have access to the model’s sources, ensuring that its claims can be checked for accuracy and ultimately trusted.
RAG lifecycle consists of Data Ingestion and Data Querying (Retrieval + Synthesis).
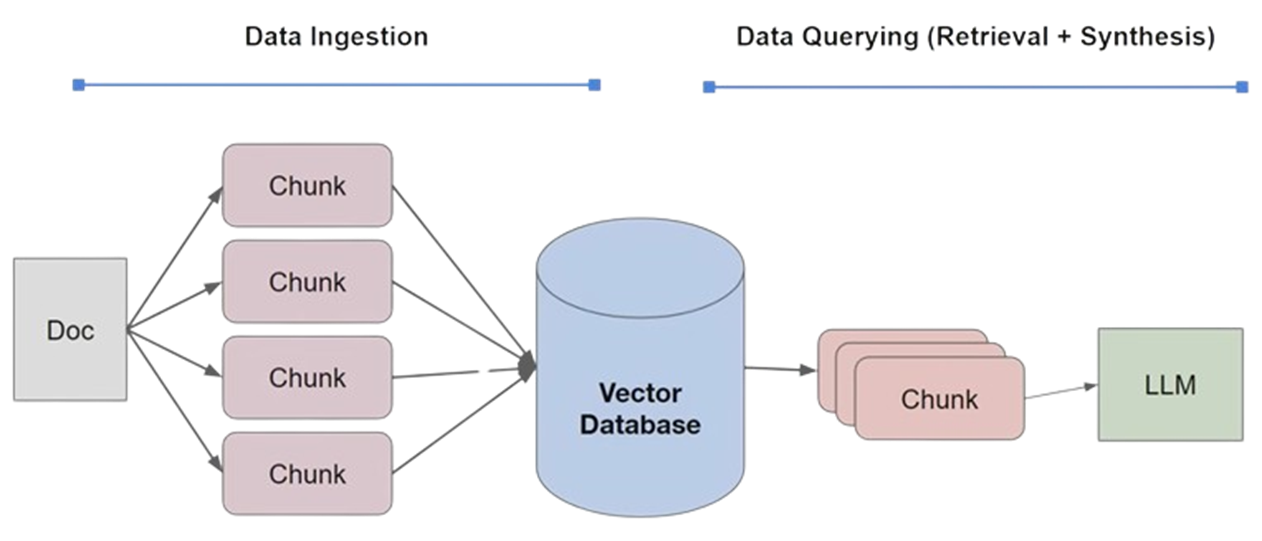
Data Ingestion is where we provide LLM with domain knowledge and up to date events. In this workflow, datasets (PDF, DOCX, TXT, HTML etc.) are first divided into smaller segments or chunks. These chunks are then transformed into embeddings using an embeddings module and then stored in a vector database for efficient retrieval.
When a user submits a query in a chat application, the backend system conducts a search to find relevant context. It combines this context with a custom prompt and utilizes a Language Model (LLM) acting as a summarization agent. The LLM’s role is to generate human-like responses to the query, ensuring that the answers are coherent and contextually relevant.
Over the past few years, RAG systems have evolved from Naive RAG to Advanced RAG and Modular RAG. This evolution has occurred to address certain limitations around performance, cost, and efficiency.
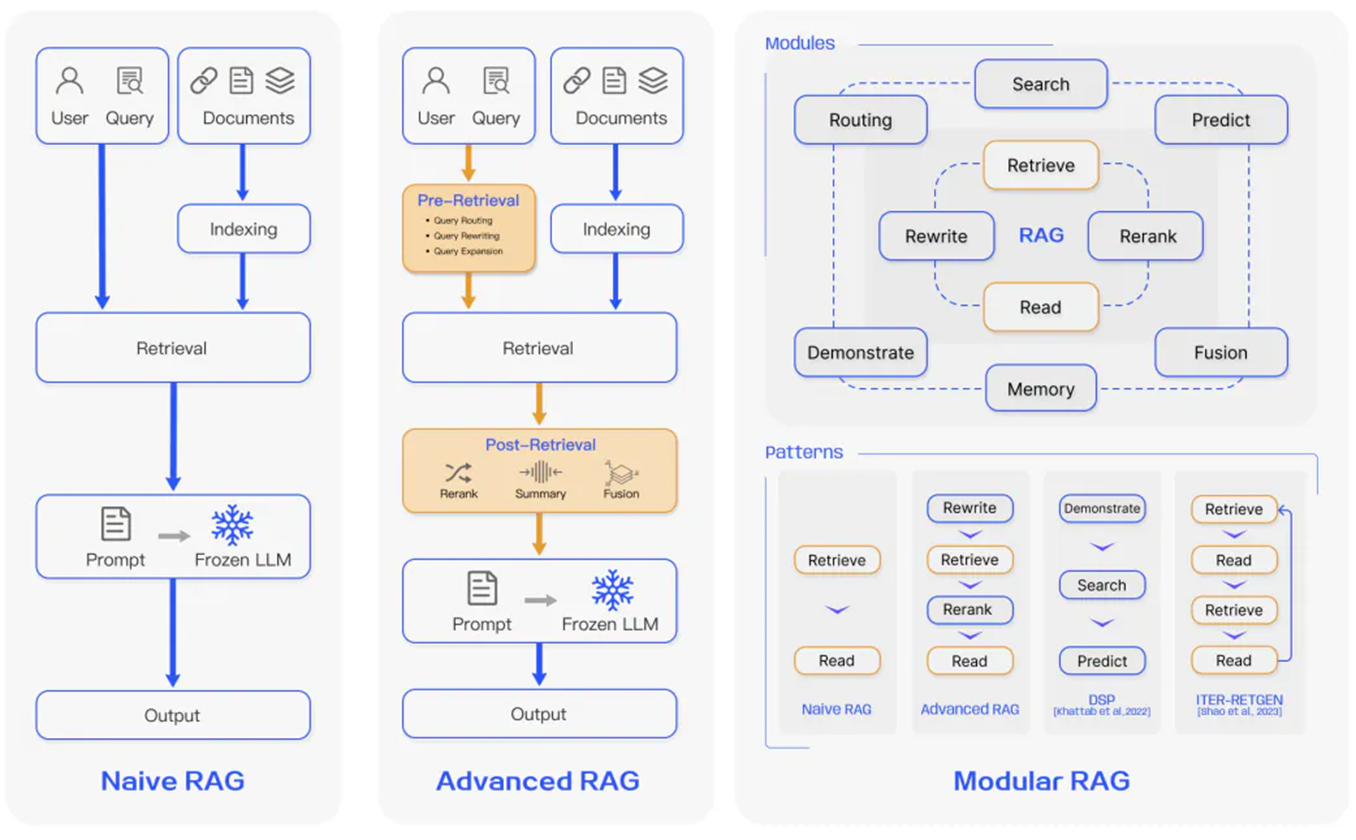
Naive RAG follows the traditional aforementioned process of indexing, retrieval, and generation. In short, a user input is used to query relevant documents which are then combined with a prompt and passed to the model to generate a final response. Conversational history can be integrated into the prompt if the application involves multi-turn dialogue interactions.
Advanced RAG helps deal with issues present in Naive RAG such as improving retrieval quality that could involve optimizing the pre-retrieval, retrieval and post-retrieval processes.
Pre-retrieval optimizations focus on data indexing optimizations as well as query optimizations. Data indexing optimization techniques aim to store the data in a way that helps you improve retrieval efficiency, such as:
The retrieval stage aims to identify the most relevant context. Usually, the retrieval is based on vector search, which calculates the semantic similarity between the query and the indexed data. Thus, the majority of retrieval optimization techniques revolve around the embedding models:
Additional processing of the retrieved context can help address issues such as exceeding the context window limit or introducing noise, thus hindering the focus on crucial information. Post-retrieval optimization techniques summarized in the RAG survey are::
As the name implies, Modular RAG enhances functional modules such as incorporating a search module for similarity retrieval and applying fine-tuning in the retriever. Both Naive RAG and Advanced RAG are special cases of Modular RAG and are made up of fixed modules. Extended RAG modules include search, memory, fusion, routing, predict, and task adapter which solve different problems. These modules can be rearranged to suit specific problem contexts. Therefore, Modular RAG benefits from greater diversity and flexibility in that you can add or replace modules or adjust the flow between modules based on task requirements.
Given the increased flexibility in building RAG systems, other important optimization techniques have been proposed to optimize RAG pipelines including: