





The potential of LLMs is vast, but there’s a catch: even the most powerful pretrained LLM might not always meet your specific needs right out of the box. LLM responses are generated sequentially, with each word selected based on its highest probability of following the previous text, a process modifiable through the parameter known as temperature. Sometimes they nail the answer to questions, other times they reproduce random facts from their training data. If they occasionally sound like they have no idea what they’re saying, it’s because they don’t.
LLMs know how words relate statistically, but not what they mean—much like the scenario in the Chinese Room Experiment, where the manipulation of symbols doesn't convey actual understanding. Therefore, it can be argued that all responses from LLMs are, to an extent, hallucinations. But generally the term hallucination refers to instances where the output of an LLM is syntactically coherent and grammatically correct, yet is factually inaccurate or logically nonsensical.
There are many reasons to try and optimize a LLM, below are some of those:
So, how do you make an LLM align with your unique requirements? You’ll likely need to tweak or “tune” it. Currently, there are multiple prominent tuning methods:
Choosing the right approach for your applications depends on multiple factors like cost, complexity of implementation, accuracy, domain-specific terminology, up-to-date responses, transparency/interpretability and hallucinations.
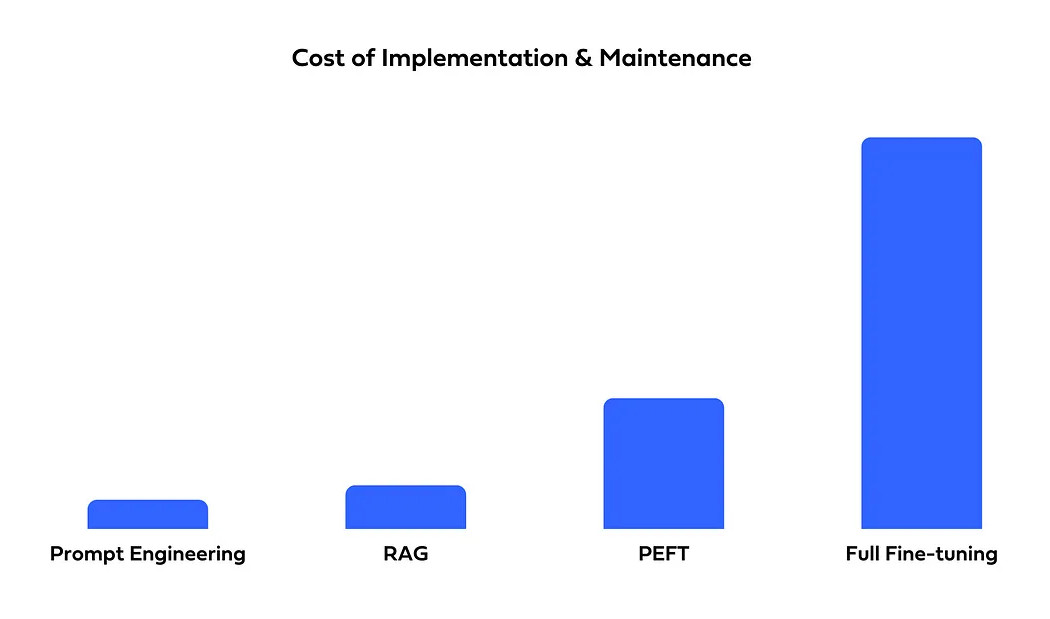
Cost is a key factor when choosing an LLM optimization method, as both implementation and maintenance expenses vary widely. Prompt engineering is the most affordable, requiring only well-crafted prompts and occasional updates. RAG incurs higher costs due to the need for multiple components like a vector store and retriever. PEFT demands more resources, as fine-tuning requires computing power and ML expertise. Full fine-tuning is the most expensive, involving extensive compute time and ongoing retraining to keep models updated.
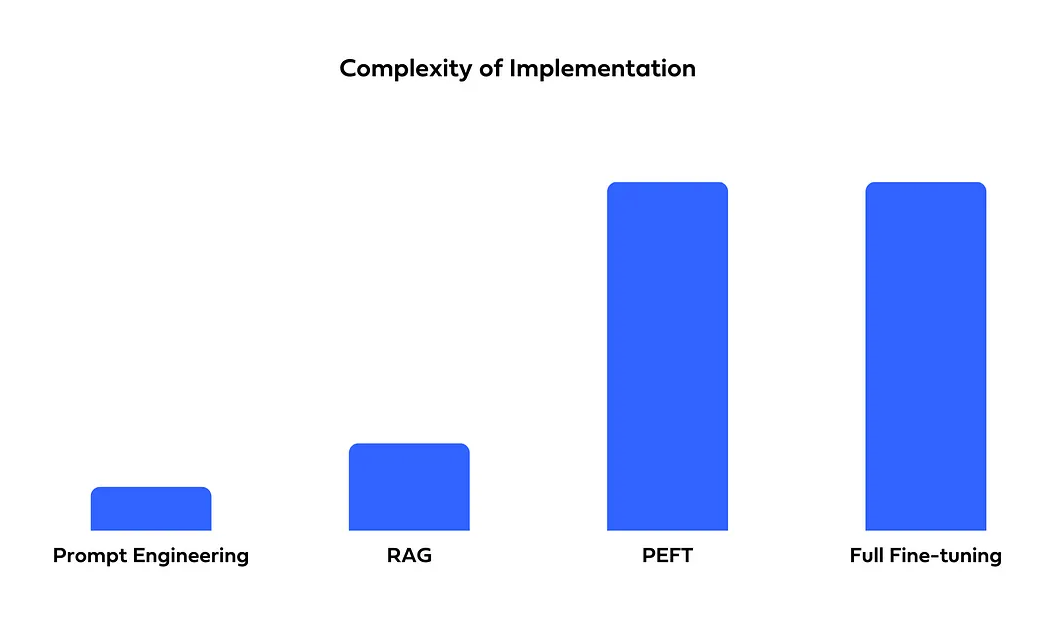
The complexity of implementation varies across methods. Prompt engineering is the simplest, requiring minimal coding and strong language skills. RAG is more complex, needing architecture and coding expertise. PEFT and Full fine-tuning are the most demanding, requiring deep learning knowledge and fine-tuning expertise to modify model weights effectively.
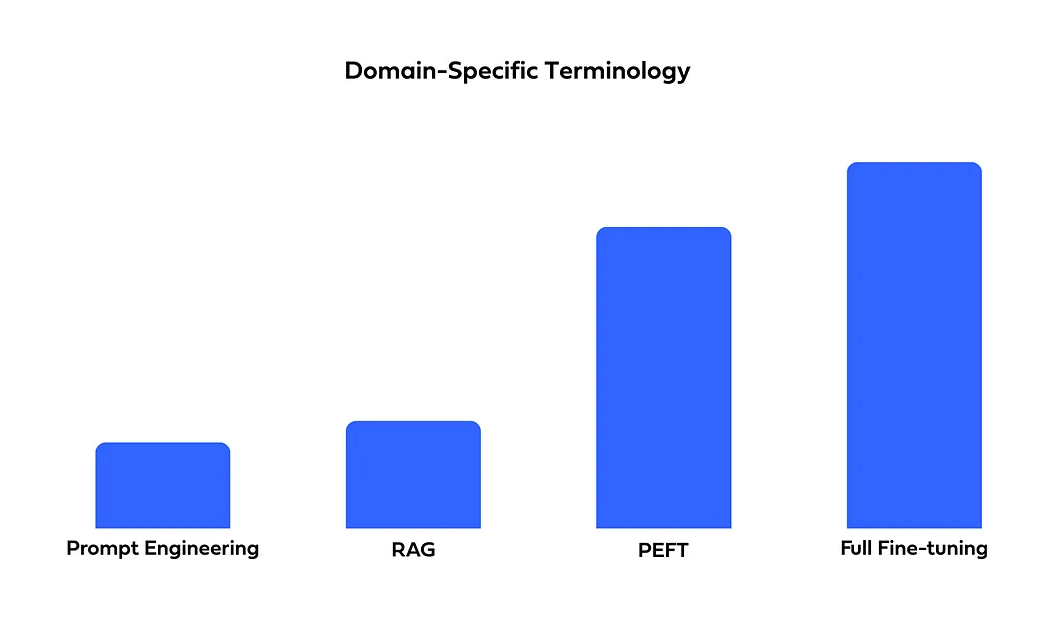
Fine-tuning is the best approach for incorporating domain-specific terminology, capturing patterns and nuances more effectively than RAG, which excels at retrieval but may lack deep domain adaptation. For tasks requiring strong domain expertise, fine-tuning is the preferred choice.
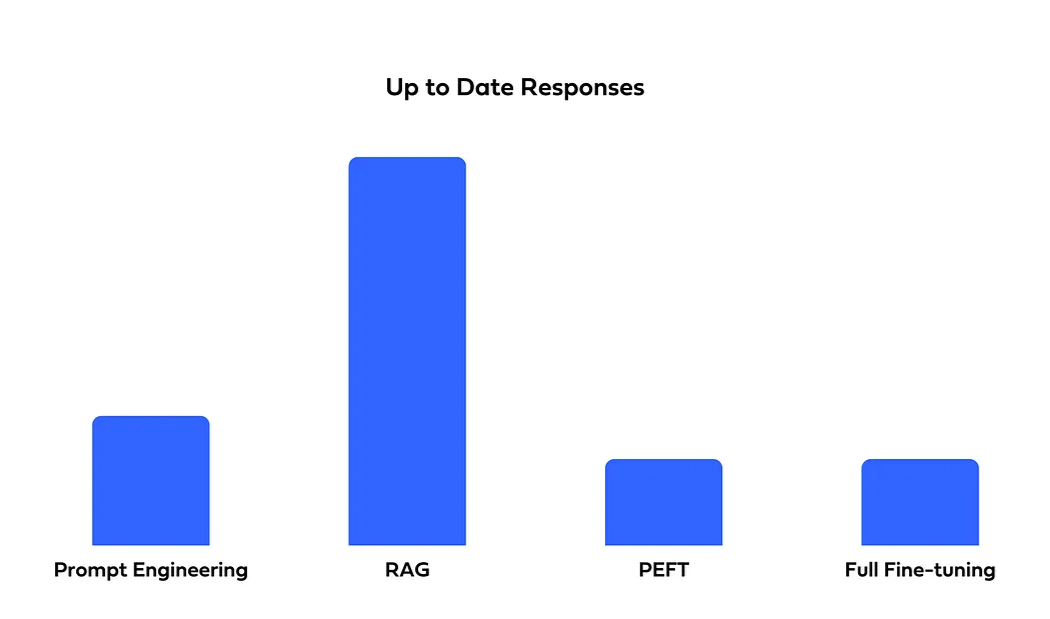
RAG is the best choice for up-to-date responses, as it retrieves information dynamically. In contrast, fine-tuned models remain static and require periodic retraining to stay current.
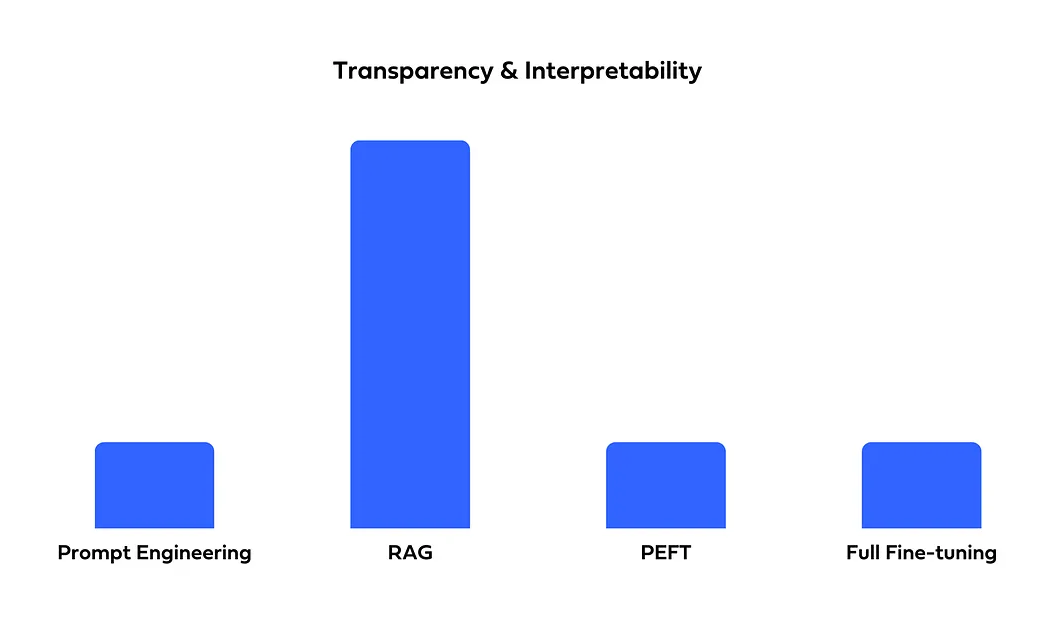
For applications requiring transparency, RAG offers better interpretability by showing which documents it retrieves. In contrast, fine-tuning acts more like a "black box," making its decision-making process less clear.
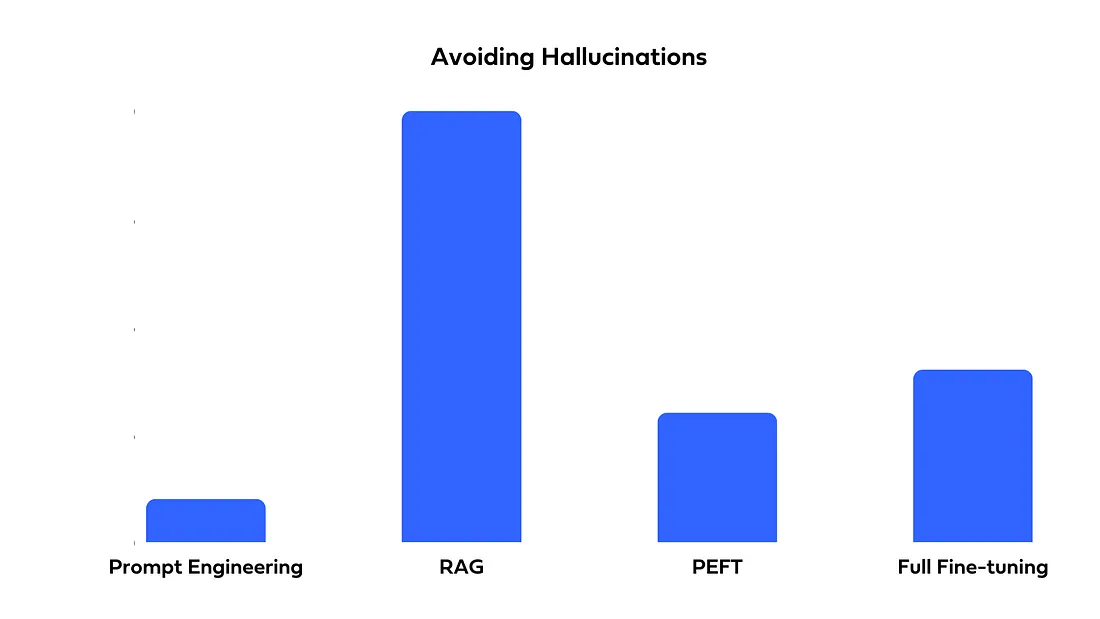
Pretrained LLMs may generate answers that are not found in their training data or the input provided. While fine-tuning can help minimize these hallucinations by concentrating on domain-specific data, unfamiliar queries might still lead the LLM to create fabricated responses. RAG mitigates hallucinations by grounding the LLM’s answers in the documents it retrieves. The initial retrieval step effectively acts as a fact-checking mechanism, ensuring that the generated responses remain within the context of the retrieved information. For tasks where minimizing hallucinations is critical, RAG is the recommended approach.
In conclusion, selecting the most suitable approach for adapting a language model requires careful consideration of various factors. Understanding the specific needs of the application is crucial, as different methods offer distinct advantages. While minimizing hallucinations may be a priority for some, others might prioritize creativity or the ability to remain updated with dynamic information. The complexity of the data and the desired outcomes can significantly influence the choice of adaptation strategy. By analyzing these aspects, businesses can make informed decisions that align with their goals, ultimately enhancing the effectiveness and reliability of their AI implementations.