





LLM agents, which are powered by LLM technology, combine various components like planning and memory to tackle complex tasks. In these setups, an LLM acts as the main controller, managing the steps needed to finish a task or address a user's needs. Additionally, these agents might need extra features like planning abilities, memory management, and tool usage.
To better motivate the usefulness of an LLM agent, let's say that we were interested in building a system that can help answer the following question:
“What's the average daily calorie intake for 2023 in the United States?”
The question above might find a solution with an LLM equipped with the necessary information. Should the LLM lack the specific knowledge required, another option is to employ a basic RAG system, where the LLM can access health-related data or reports. Let's now challenge the system with a more intricate question, like this one:
“How has the trend in the average daily calorie intake among adults changed over the last decade in the United States, and what impact might this have on obesity rates? Additionally, can you provide a graphical representation of the trend in obesity rates over this period?”
Merely relying on an LLM wouldn't cut it for answering such a question. You might think to pair the LLM with an external knowledge source to create a RAG system, but that alone likely won't handle the complexity of the question. The reason being, the question demands the LLM to dissect the task into smaller pieces that can be tackled using tools and a series of steps to reach the desired answer. One potential fix is to create an LLM agent that taps into a search API, health-related documents, and both public and private health databases. This setup could deliver the necessary details about calorie intake and obesity.
In addition, the LLM will need access to a "code interpreter" tool that helps take relevant data to produce useful charts that help understand trends in obesity. These are the possible high-level components of the hypothetical LLM agent but there are still important considerations such as creating a plan to address the task and potential access to a memory module that helps the agent keep track of the state of the flow of operations, observations, and overall progress.
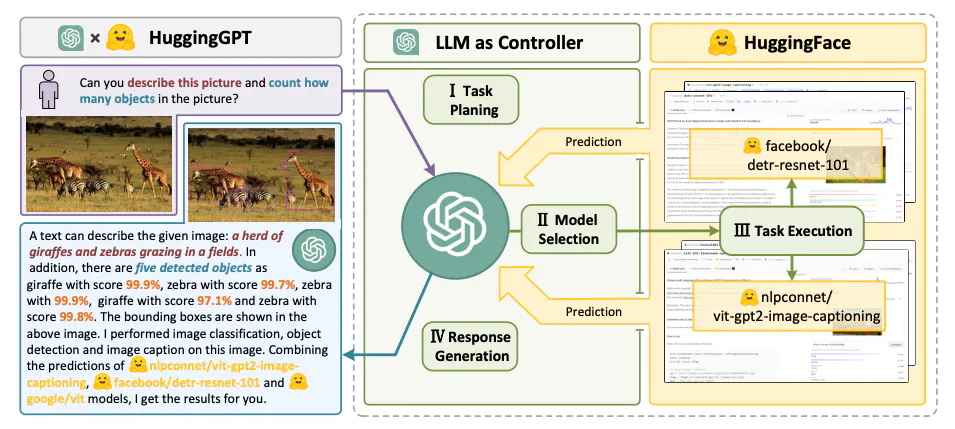
AI agents operate through a structured four-step process to efficiently handle user queries and complex tasks. First, task planning breaks down the problem into manageable subtasks, enabling better reasoning and structured execution. Next, model selection determines the most suitable LLM or external tool to handle each step, optimizing performance based on the task's requirements. Then, task execution involves the agent carrying out planned actions, leveraging memory, retrieval mechanisms, and external APIs as needed. Finally, response generation compiles the results into a coherent and meaningful output, ensuring clarity and relevance for the user. By integrating these steps, AI agents can reason effectively, adapt to dynamic environments, and continuously improve their performance through feedback and memory.
Generally speaking, an LLM agent framework can consist of the following core components:
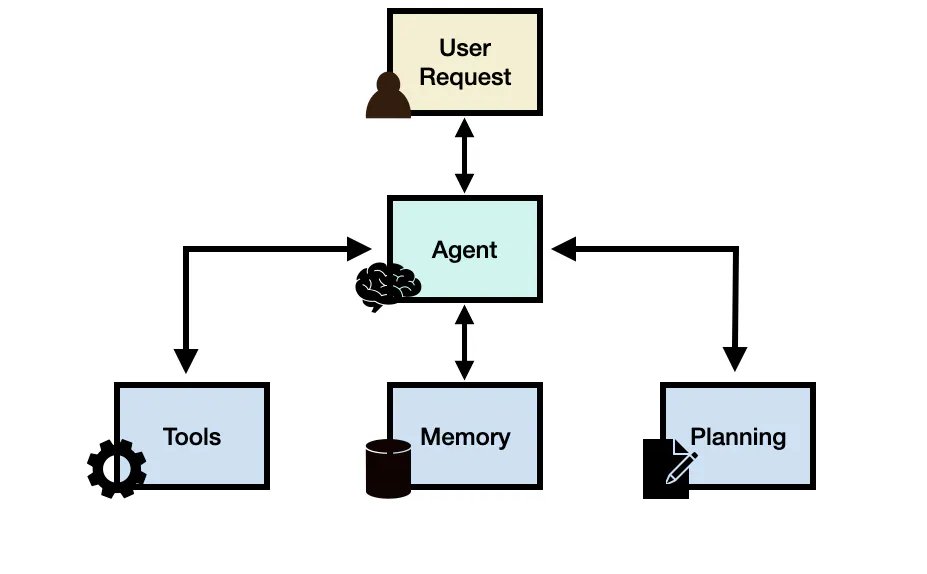
A general-purpose large language model (LLM) acts as the system's main brain, agent module, or coordinator, activated through a prompt template that defines its operations and available tools. While not mandatory, an agent can be assigned a persona or profile, typically embedded in the prompt, detailing its role, personality, and social or demographic traits.
The planning module helps an agent break down complex tasks into manageable subtasks, improving its ability to reason and find solutions. Without feedback, planning relies on an LLM to generate a structured execution plan using techniques like Chain of Thought (single-path reasoning) and Tree of Thoughts (multi-path reasoning). However, long-horizon planning benefits from feedback mechanisms that allow the model to refine its approach iteratively. Techniques such as ReAct and Reflexion enable agents to learn from past actions, improving solution quality through trial and error. ReAct, for instance, interleaves Thought, Action, and Observation steps, incorporating environmental, human, or model feedback to enhance decision-making.

The memory module stores an agent's internal logs, including past thoughts, actions, observations, and interactions with users. It consists of short-term memory, which retains context information for the current situation using in-context learning but is constrained by the LLM's context window, and long-term memory, which preserves past behaviors and thoughts using an external vector store for scalable retrieval.
Hybrid memory combines both types to enhance long-range reasoning and experience accumulation. Agents can use various memory formats, such as natural language, embeddings, databases, or structured lists, and hybrid approaches like Ghost in the Minecraft (GITM), which employs a key-value structure with natural language keys and embedding vector values. Together, the planning and memory modules enable agents to adapt dynamically, recall past behaviors, and plan future actions effectively.
Tools correspond to a set of tool/s that enables the LLM agent to interact with external environments such as Wikipedia Search API, Code Interpreter, and Math Engine. Tools could also include databases, knowledge bases, and external models. When the agent interacts with external tools it executes tasks via workflows that assist the agent to obtain observations or necessary information to complete subtasks and satisfy the user request. In our initial health-related query, a code interpreter is an example of a tool that executes code and generates the necessary chart information requested by the user.